Some think
用skip list存储posting的话是可以实现方便的添加和删除元素的,其效率的话也算比较高,相当于每次做一个二分查找.但是这样的话可能空间占用会多一些.
根据理论计算是对于n个元素的一个skiplist 需要少于2n个node 就可以. 由于一个node节点是原来的4倍(由于一个地址长度是8,然后一个int 是4, 那么对齐后就是16),所以整体来说就是8倍.
An Exploration of Postings List Contiguity in Main-Memory Incremental Indexing 这篇文章介绍了如何在内存中存放postings, 如果在内存中隔得比较远的话,会影响性能,但是如果连续的话,需要一些控制,这里给了一个 tradeoff. 也许对于目前也有一些指导意义.
Fast Incremental Indexing for Full-Text Information Retrieval 文章提到说,在他们的情形中 over 90% of the inverted lists are less than 1000 bytes (in their compressed form), and account for less than 10% of the total inverted file size. Furthermore, nearly half of all lists are less than 16 bytes. This means that many inverted lists will never grow after their initial creation. Therefore, they should be allocated in a space efficient manner。 这个启发我们在做设计的时候要首先考虑 index 的内容等特性。文章中设计的inverted list不是 a single object of the exact size,而是 using a range of fixed size objects,here the sizes range from 16 to 8192 bytes by powers of 2 (i.e., 16, 32, 64, …, 8192). 在create的时候,分配可以装下的最小的 size。当超过这个size之后,分配一个下一档的内存,然后复制过去,free掉当前的内存。当达到最大object size,不是再扩大这个内存size,而是生成一个 8192的 linked list object,然后把这个的尾指针之过去。感觉在一定程度上类似于STL里面的Vector的设计。
The largest objects are each allocated intheir own physical segment and managed by a large object pool. The smallest (16 byte) objects are stored in 4 Kbyte physical segments, 255objectspersegment, and managed by a small object pool. The remaining objects are stored in 8 Kbyte physical segments, where each segment stores objects of only one size, and contains as many objects of that size as will fit. These objects are managed by a medium object pool。
是否需要支持delete document. 或者说现在对于document的delete是通过block doc完成的吗?
理论上来说, in memory index的部分应该是比较 hot 的doc,或者说是 static rank 分数比较高的那部分doc.

看了一个google 的设计文档,发现我们的设计和他们很相似啊. google talk about index
规模是在设计中必须考虑的一个问题.
in memory index format from papers
Here are several papers I read about in-memory index structure. Nearly all paper considered on posting list dynamic extending, but in which kind of method, I think we need to do some experiments according to our index. And posting lists are implemented as arrays for data continuous.
Earlybird: Real-Time Search at Twitter
This paper designed an in-memory structure optimized for single-writer, multiple-reader. The index can be divided into:
- Term dictionary(a simple hash table, uses open addressing on primitive arrays)
- Term data(held in parallel arrays)
- number of postings for the term
- pointer to the tail of the postings list
- Active index
- Each posting is a 32-bit integer(24 bits for document-id, 8 for term position)
- Stored in an array, cache friendly
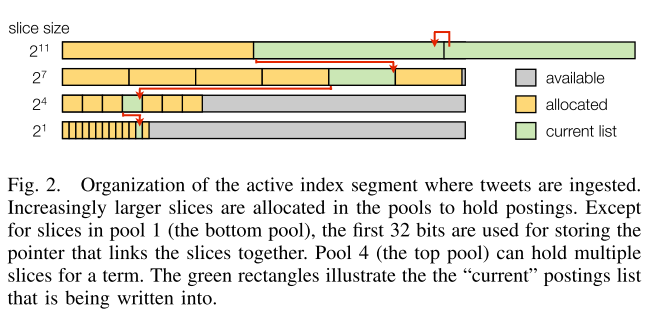
- allocation of space for postings lists.
- Postings lists vary significantly in size, since term and document frequencies are Zipfian
- create four separate “pools” for holding postings.
- In each pool, the slice sizes are fixed: they are 2^1, 2^4, 2^7, and 2^11
- The first time a term is encountered, a postings list is created in the first pool (i.e. holds 2 elements)
- Each slice (except 2^1) reserves the first 32-bits for a pointer to the previous slice
- Concurrency
- Limit to a single writer per index segment for simplicity
maxDocis used to divide write and read process. Readers ignore docs encountered greater than maxDoc.

After achieve to a threashold, convert index from a write-friendly structure into an optimized read-only structure. Postings are divided into “long” and “short”(less than 1000). For long postings, use a block-based compression scheme similar in spirit to PForDelta and the Simple9 family of techniques.
Fast Incremental Indexing for Full-Text Information Retrieval
This paper mentioned in their case, over 90% of the inverted lists are less than 1000 bytes (in their compressed form), and account for less than 10% of the total inverted file size. Furthermore, nearly half of all lists are less than 16 bytes. This means that many inverted lists will never grow after their initial creation. Therefore, they should be allocated in a space efficient manner。It designed an inverted list struct using a range of fixed size objects, not a single object of the exact size,here the sizes range from 16 to 8192 bytes by powers of 2 (i.e., 16, 32, 64, …, 8192). 在create的时候,分配可以装下的最小的 size。当超过这个size之后,分配一个下一档的内存,然后复制过去,free掉当前的内存。当达到最大object size,不是再扩大这个内存size,而是生成一个 8192的 linked list object,然后把这个的尾指针之过去
The largest objects are each allocated intheir own physical segment and managed by a large object pool. The smallest (16 byte) objects are stored in 4 Kbyte physical segments, 255objectspersegment, and managed by a small object pool. The remaining objects are stored in 8 Kbyte physical segments, where each segment stores objects of only one size, and contains as many objects of that size as will fit. These objects are managed by a medium object pool。
An Exploration of Postings List Contiguity in Main-Memory Incremental Indexing
This paper put all index into memory, but they only do some experiment for index speed and query evaluation after indexing the entire collection. It has no work in serve and index at the same time. The structure is:

Data is first added into each buffer map. When the docid buffer for a term fills up, “flush” all buffers associated with the term, compressing the docids, term frequencies, and term positions into a contiguous block of memory as follows: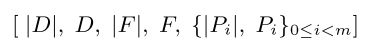
D represents data for docid(compressing using PForDelta, blcok size b = 128), F represents TF, P_i for postion.
To achieve increasingly better approximations of contiguous postings lists, this paper propose a approach of changing the memory allocation policy for the buffer maps.
Whenever the docid buffer for a term becomes full (and thus compressed and flushed to the segment pool), expand that term’s docid and tf buffers by a factor of two (still allowing the term positions buffer to grow as long as necessary). This means that after the first segment of a term is flushed, new docid and tf buffers of length 2b replace the old ones; after the second flush, the buffer size increases to 4b, and then 8b, and so on. To prevent buffers from growing indefinitely, we set a cap on the length of docid and tf buffers. That is, if the cap is set to 2^mb, then when the buffer size for a term reaches that limit, the buffer is broken down into 2^m segments, each segment is compressed as described earlier, and all 2^m segments are written at the end of the segment pool contiguously.
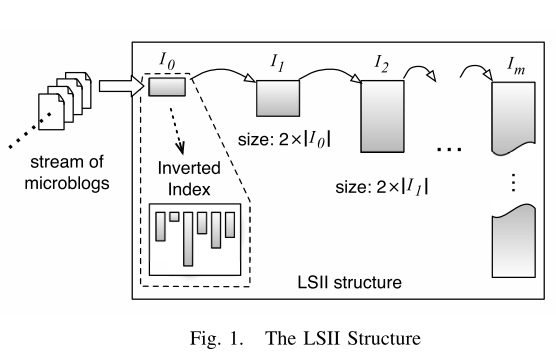
LSII: An indexing structure for exact real-time search on microblogs
Log-Structured Inverted Indices (LSII), is similar in spirit to the Log-Structured Merge-Tree: It contains a sequence of inverted indices I0,I1,…,Im with exponentially increasing sizes, as illustrated in Figure below. When a new document arrives, it is first inserted into the smallest inverted index I0 – this incurs little overhead given the tiny size of I0. When the number of documents indexed by I0 exceeds a certain threshold, we merge the entries of I0 into I1, and we empty I0; in turn, the entries in I1 are flushed into I2 when I1 gets to a certain size, and so on. This considerably reduces the amortized update cost per document, since (i) each document can be only involved in a small number of index mergers, and (ii) the index mergers can be performed in a much more efficient manner than inserting all documents into an inverted index one by one.
For each inverted index Ii, it maintains a hash table that maps the document id indexed by Ii to a triplet$
During query processing, all inverted indices are scanned simultaneously using the Threshold Algorithm.
On main-memory flushing in microblogs data management systems
Focus on how to flush to disk. This paper proposes kFlushing policy that exploits popularity of top-k queries in microblogs to smartly select a subset of microblogs to flush. kFlushing is mainly designed to increase memory hit ratio. To this end, it identifies and flushes in-memory data that does not contribute to incoming queries.
呼呼呼山
2019-07-15 11:48:29