如果说移动化对于哪个互联网产业冲击最大, 无疑是搜索引擎, 从百度的市值就可以明显的看到,从之前BAT的王者, 到现在一个拼多多等于两度.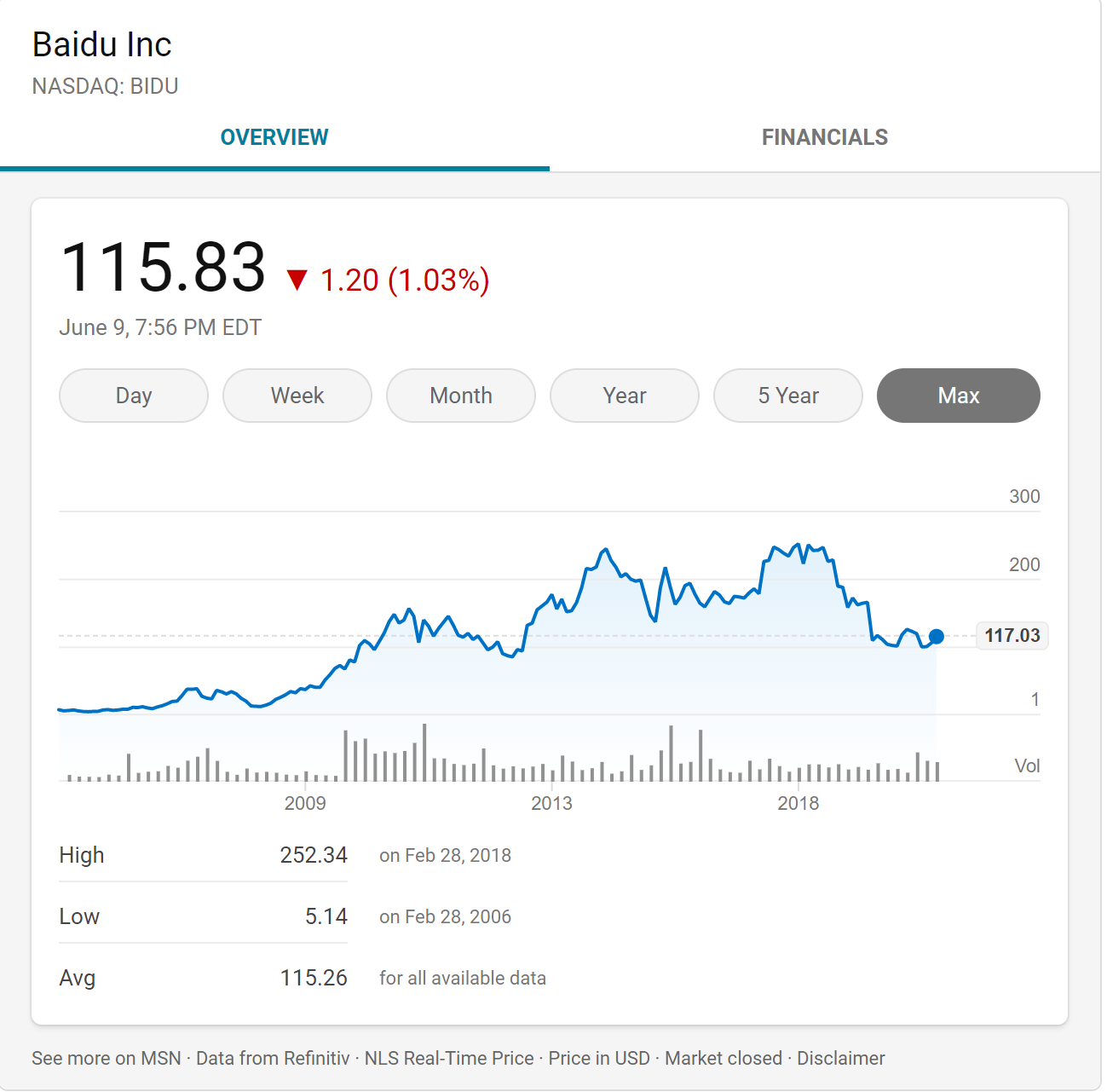
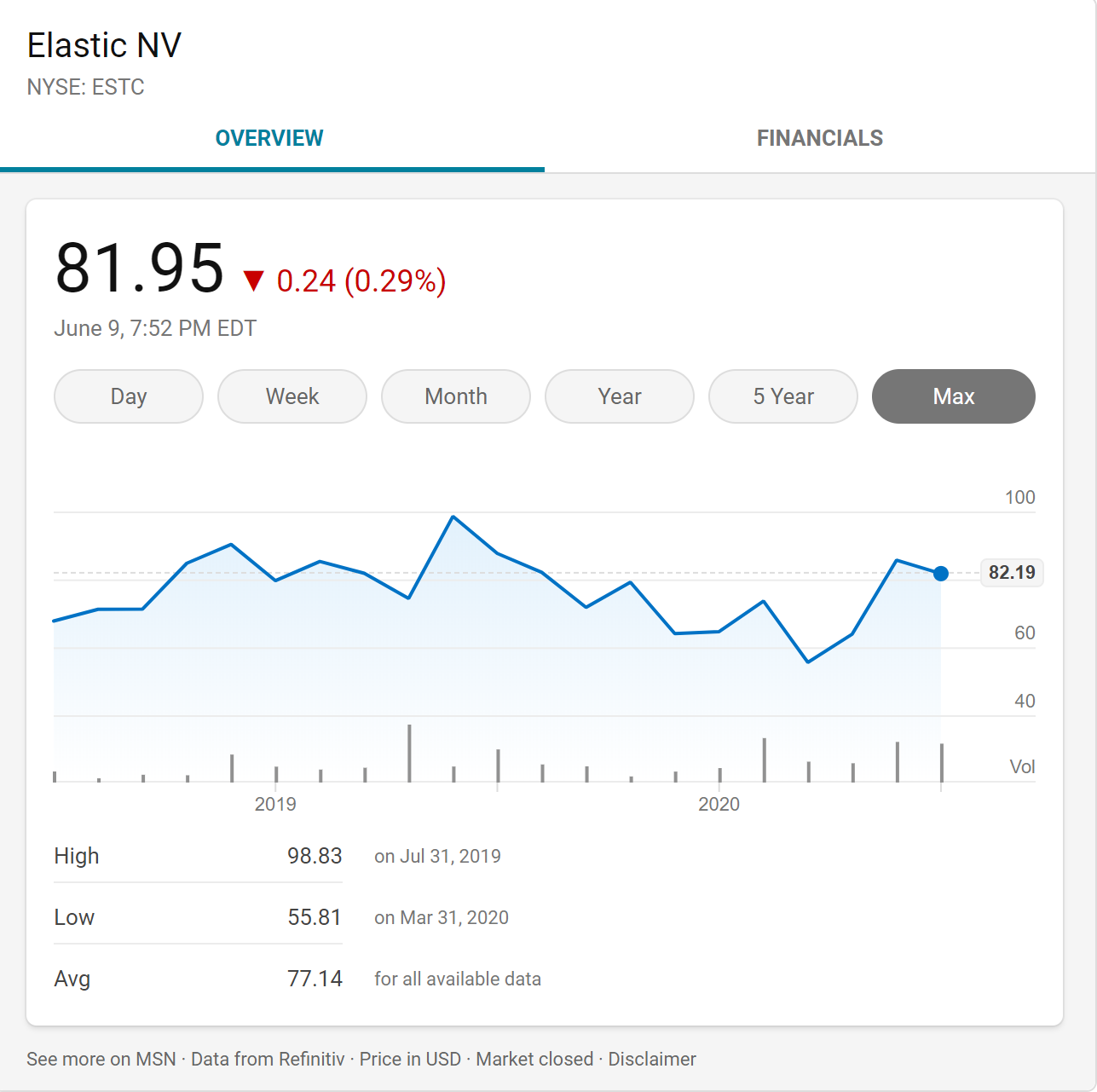
由于越来越多的内容封锁在自己的领域(以微信公众号为主), 以及轰轰烈烈的去Web化(必须用移动端APP访问才可以), 属于搜索引擎的时代似乎过去了, 但搜索的时代一直存在, 从微信的搜一搜到头条搜索再到阿里的神马搜索, 以及 Elastic Search 居高不下的股价, 无不说明着搜索一直在.
从一般意义上来说搜索引擎分为通用搜索引擎, 譬如 Google, Bing, Baidu之类的, 还有专用的搜索引擎, 例如各种应用内搜索. 对于搜索引擎的一个重点就是其索引的文档的数量多少, 只有索引了足够多的文档, 才可能根据用户输入的 query 得到最好的匹配. 但现在随着封闭化的出现, 通用搜索引擎所能索引到的好文档数量肯定是在减少.
从分布式的实现来说, 我们可以根据分片方式将其分成 term-shard 和 document-shard, 也就是在做分布式的时候, 我们是按照不同的 term 来划分, 还是按照不同的文档来划分. 前者肯定是更加省时的, 因为一次查询就可以把所有的文档都查询到, 但是其不易扩展, 当一个文档更新的时候, 所有的分片理论上都需要更新, 另外就是不稳定, 肯定有些词会相比起来更加热门一些, 所以到这些词的 query 也就更多一些, 而对这些机器的负载也就更大, 所以也就更不稳定. 当然我们可以给那些热门词, 更多的 replica 从而降低每天机器的负载, 但是由于一些突发时间造成某些词的搜索量急剧增加的情况是没法解决的, 例如 covid-2019, 这个词根本没法预测到. 所以现在大家都比较喜欢用的方法是 document-shard, 就是按照 document 来做分片, 每台机器上包含一定document的所有的 term, 这样一来每次 query 都要到每台机器上都去执行一遍, 然后再做一个合并才能得到比较好的结果, 相比起来这种的 cost 就会大一些, 当然相应的好处就是, 某台机器挂了, 对于 query 结果的影响比较小, 做更新和扩展也容易的多.
而在做查询的时候, 都用一个叫做 index 的文件. 一般使用的都是倒排表, 也即 inverted index. 正排就是指的那些从文档到其包含的 term 的映射关系, 而倒排就是反过来是从term 到文档的映射. 这样一个查询动作就变得很简单了, 就是找到相应的 term, 然后获得其所对应的所有的文档(一般称作 posting), 然后将这些posting 做一个与操作就好了. 做与操作的一个最简单的方法当然是直接用二进制的位操作, 但显然对于我们那么大数量文档情况是不划算的, 另外一个比较朴素的想法就是如果两边的posting都是排序的的话, 那么我们只需要遍历一遍就可以解决问题了.现在基本上也都是这么做的, 也就是对于整个index 包含的所有文档做一个排序, 然后依据此排序将其填到每个term的posting中去. 当然这里的排序就可以做一些操作, 通常我们可以把质量比较好的文档放在前面, 这是由于对于大部分查询来说, 我们不可能把所有匹配的结果都返回, 大概率会查一定程度就结束了, 所以按照质量排序的话, 质量好的文档就更可能被用户看到
一个文档能被用户看到, 首先就是需要被match出来. 普遍有两种match方法, 一种是朴素的方法, 就是根据 term 去查找包含这个term的文档, 然后做and/or 操作, 当然为了提高准确性, 在 match 之前, 我们可能对 term 做一些拼写检查和理解之类的, 例如把 microsft 修改成 microsoft 之类的. 但是有些情况下这种就会遇到一个比较尴尬的情形, 假设我们搜索 “某个人的生平”, 但是对于那些介绍了这个人但是文章中没有出现 “生平”字样的文档, 都无法正确的match到, 对于这种的话一般就是借助于神经网络将这些词和文档都转换成向量(vector), 然后做匹配. 另外目前还有一个比较难以处理的搜索的类型, 譬如”北京的餐馆, 不要日料”, 按照上面的搜索方式, 那么大概率查询结果都是北京的日料店, 这种只能依靠自然语言理解水平的进一步提高了.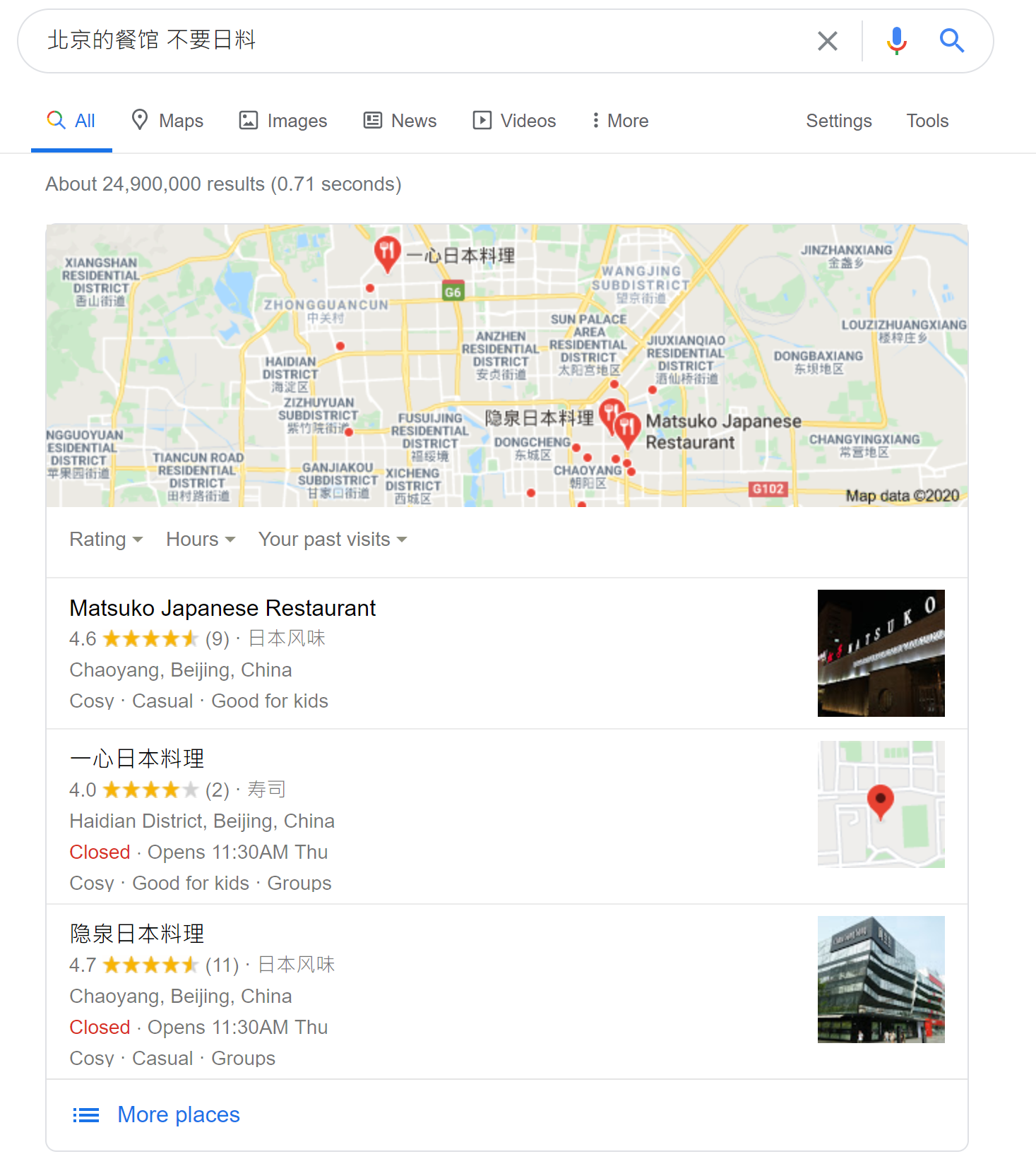
呼呼呼山
2020-06-10 21:08:04