Disk allocation unit size, 故名思议, 是硬盘里面的分配单元. 也就是说当我们对硬盘进行划分的时候,是以多大的单元把数据均匀分配的. 这个概念并不是硬盘上的概念, 虽然对于硬盘也有最小的处理单元, 例如对于一个普通的机械硬盘, 由于扇区的划分, 可能一个最小的单位就是 4KB, 即使你只想读 1Byte的数据, 他还是要读取 4KB 的数据, 只是并没有把你不需要的那部分返回给你. 对于文件系统, 文件系统里的 Allocation 是一个类似于内存分配的概念, 为了可以更方便的索引, 我们不能把整个硬盘按照 Byte 或者 Bit 来拆分, 但是如果拆分单元过大的话, 那么就会造成很多空间的浪费, 对于一个 64KB 分配单元, 即使是一个只有一个字节的文件, 其占据的硬盘空间也是64KB.
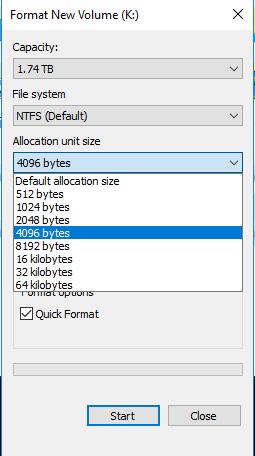
分配单元的大小一般会没有什么影响, 但是当我们要用多快数据盘来保存数据的时候, 情况就变得比较重要了, 对于随机读写支持最好的 RAID0. 由于我们要把两块硬盘以条带方式组合(Striped volume)起来, 那么当如果我们以 4K 来作为 allocation unit size, 那么整个文件就会按照 4K 这种单元随机的分布到两块盘上, 此部分在 NTFS 文件系统中是完全不可控的, 那么一个文件会以什么方式分布到两块盘上就完全听天由命了. 这时候如果我们发起 16KB 大小的 IO, 就有可能把这个 16KB 分成 0 + 4, 1 + 3, 2 + 2 这三种情况. 等于也就是我们一个从应用程序方发出来的单个 IO 请求, 到了硬盘上就变成了两个 IO 请求, 而这种请求在操作系统层面上统计还是只视作一个 IO event, 只能单独查看每一个 IO event 才能确定这种情况. 同时另一方面, 当分配单元过大的时候, 我们又可能造成 IO event 的分配不均匀, 导致某一块盘的 IO 更多, 从而更早的达到 bottleneck.
综合起来说就是, 对于 allocation unit size 的确定要根据实际场景里面的 IO event 的主要的 size, 尽量的保证该 allocation size 要大于 IO size, 在此基础上再尽量小, 从而可以让数据可以尽可能的平均分配到多块盘上.
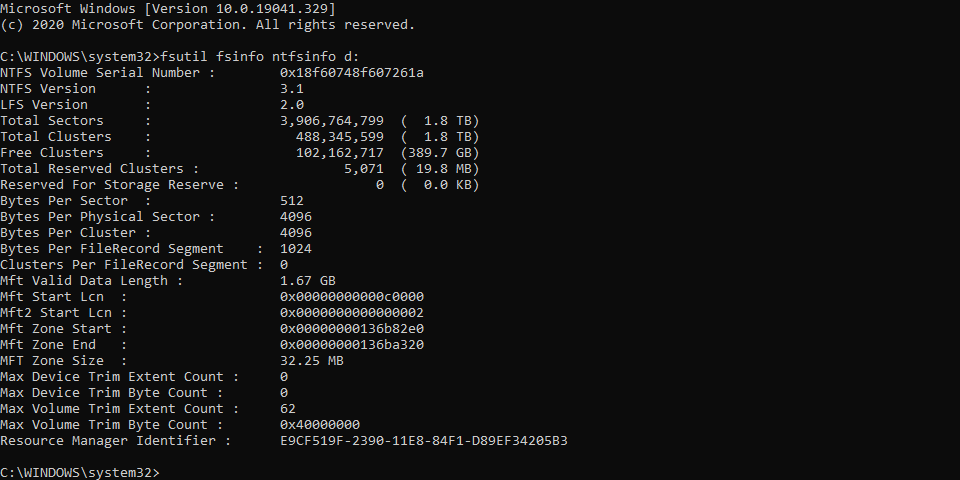
那么如何确定当前硬盘的 allocation unit size 是多少呢? 一种方式是就是尝试格式化, 会显示当前的 unit size. 另一种是用命令, 可以使用命令
|
|
其中的 Bytes Per Cluster 就是当前的 allocation size.
呼呼呼山
2020-06-23 13:55:05